2018.8.23 Wikipedia頻出単語
放置の限りを尽くしてしまっていたので、なんとかして記事を書くことにする。
友人と英単語クイズを出し合って久しぶりに受験生の頃を思い出すなんてことをしていた。
覚えていたはずの単語が昔ほどすらすら出ないなどと老いを感じる一方で、英単語を効率的に覚えるツールを作りたいと考えていたことを思い出し、取り組むことにした。
そのために、まずは「覚えるべき英単語」としての頻出単語を自分で求める必要がある。
「覚えるべき英単語」を人間が恣意的に決めることにしっくりきてなかったこともあって、大量の文章から頻度でランキングを作り、その上位を「覚えるべき英単語」とみなせば、効率の良い単語帳が出来上がると考えた。
大量の文章をどこから用意してくるのか、という話になるが、今回はご存知のWikipedia(英語版)を用いることにする。
Wikipediaから本文のみを持ってくるAPIとしてMediaWikiというものが用意されている。MediaWiki APIを使ってWikipediaの情報を取得を参考にさせていただいた。
手順としては、MediaWiki APIを通じて、指定したタイトルの記事本文を取ってきて、HTMLタグの中に含まれる文字列から英単語を正規表現でうまいこと抽出し、pandasのSeriesに変換する。
pandasのSeriesまで持ってくれればあとは秒殺である。
value_countsを使って頻度でソートし、それを各単語をキーとして結合し、全記事の情報を一か所に集めたDataFrameを作る。
珍しくコードにしっかりとコメントを書いたので、Wikipediaの本文を大量に取得したくてうずうずしている人の参考になれば幸いである。
#データ分析用の高速なライブラリ
import pandas as pd
# HTMLタグ解析用
from pyquery import PyQuery as pq
# APIにGETリクエストを送り、レスポンスを受け取る
import urllib
# 正規表現
import re
# jsonでAPIから送られてくるデータをPythonの辞書に変換する
import json
# 使用する記事のタイトル
# ある程度無作為抽出し、かつ、ある程度本文が長いものを選んだ。
# この記事を選ぶ作業は結果に大きく影響するので慎重に行うべき!
titles = """
Earth
Moon
soar
Jesus
owl
perception
storm
format
Mahatma_Gandhi
wood
cheque
Chile
flash
Animation
acid
apparatus
Supersilent
Mooloolah_Valley,_Queensland
Hacking_Democracy
Russians_in_Latvia
C♯_(musical_note)
Frequency
Nominalization
""".split()
def main():
# 各記事に含まれる全単語を含んだSeriesのリスト
srs = [words_contained_in(title) for title in titles]
# 全ての単語が各記事に出現した回数
frequency = pd.concat([words.value_counts() for words in srs],
axis=1, sort=False)
# 記事関係なく全ての単語の出現回数をソートし、csvファイルに出力
frequency.sum(axis=1).sort_values(ascending=False).\
astype(int).to_csv('all_words.csv')
# 単語ごとに何個の記事に出現したかを調べソートし、csvファイルに出力
(frequency >= 1).sum(axis=1).sort_values(ascending=False).\
to_csv('ranking.csv')
def wikitext_by_title(title):
"""記事名を与えると、本文を返す。
"""
params = {
'format': 'json',
'action': 'query',
'titles': title,
'prop': 'extracts',
'redirects': 'true'
}
dic = media_wiki_api(params)['query']['pages']
html = list(dic.values())[0]['extract']
return pq(html).text()
def media_wiki_api(params):
"""APIに渡すパラメータを辞書で引数とし、レスポンスのテキストデータを返す。
"""
params_encoded = urllib.parse.urlencode(params)
url_wiki = 'https://en.wikipedia.org/w/api.php'
res = urllib.request.urlopen(f'{url_wiki}?{params_encoded}')
return json.loads(res.read().decode('utf-8'))
def words_contained_in(title):
"""記事名を与えると、その記事の英単語をpd.Seriesとして返す。
"""
text = wikitext_by_title(title)
words = re.sub(r"[^\w]", " ", text).split()
words = pd.Series(words).str.lower()
words = words[words != title.lower()]
return words[~words.str.match(r'[0-9]')]
def frequent_words(words_concat, n_thres=5):
"""全記事の各単語の頻度をpd.DataFrameとして与えると、
記事の中にその単語がn_thres回以上含まれるような記事が
全記事の半分以上存在するような頻出単語を返す。
"""
ww_sum = words_concat[(words_concat >= n_thres).any(axis=1)].copy()
ww_sum = ww_sum[(ww_sum > 0).sum(axis=1) >= ww_sum.shape[1] // 2]
ww_sum['sum'] = ww.sum(axis=1)
ww_sum = ww_sum.sort_values('sum', ascending=False).\
fillna(0).astype(int)
return ww_sum.drop(columns=['sum'])
さて、肝心の結果である。
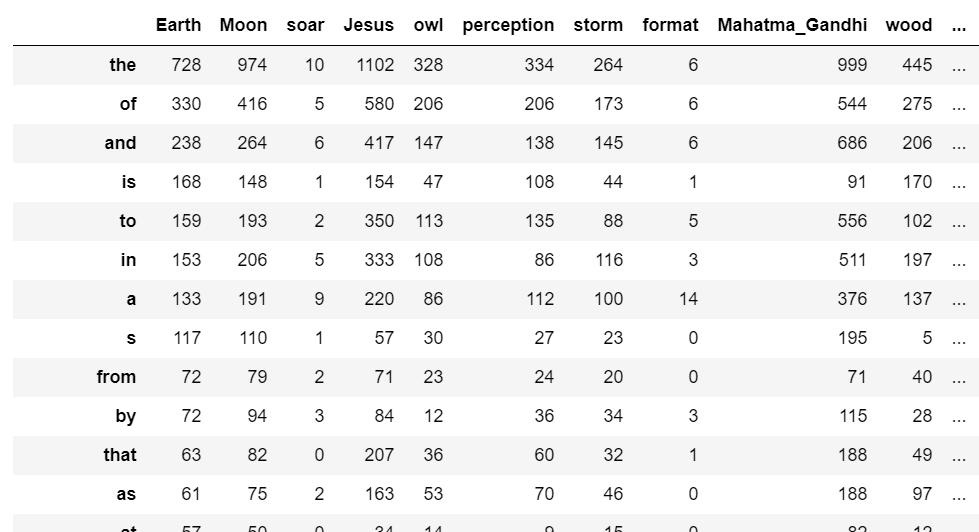
上の表を見ると、多くて当然の英単語が上位に来ている。
重複を除いた全単語が13,000語ほどあるが、ほとんどは5回未満といった少ない出現頻度であった。
ちょうどよい難易度と考えられる上位3000位から50個抜き出すと以下のようになる。
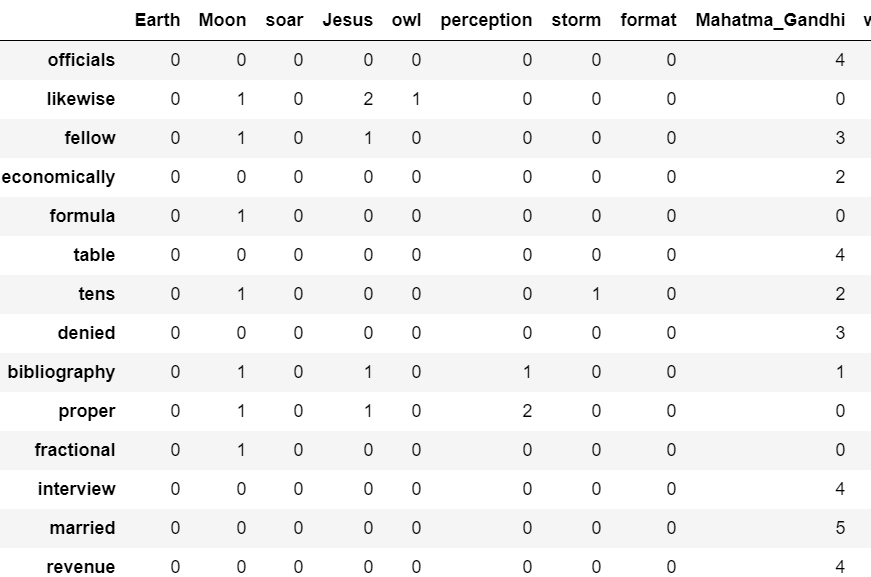
単数形と複数形や、動詞の現在形と過去形が別々にカウントされていることが若干気になるものの、欲しかったデータはそれなりに形になっているようである。
せっかくなので、13,000行のCSVを見たい人はこちらをクリック。
英単語を覚えられるタイピングゲームとか作ってみたい。
やってみて思いついたが、英単語だけではなくて、それが使われている文脈も取り出すことができる。例文が百科事典というきれいな英語なのもポイントが高い。
思い出したときに、また作業を進めてみよう。
おわり。